[Advanced Published online Journal of Computer Chemistry, Japan, by J-STAGE]
<Title:> Constructing Regression Models with High Prediction Accuracy and Interpretability Based on Decision Tree and Random Forests
<Author(s):> Naoto SHIMIZU, Hiromasa KANEKO
<Corresponding author E-Mill:> hkaneko(at)meiji.ac.jp
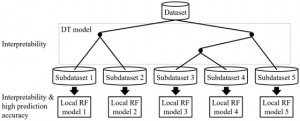
<Abstract:> Models for predicting properties/activities of materials based on machine learning can lead to the discovery of new mechanisms underlying properties/activities of materials. However, methods for constructing models that exhibit both high prediction accuracy and interpretability remain a work in progress because the prediction accuracy and interpretability exhibit a trade-off relationship. In this study, we propose a new model-construction method that combines decision tree (DT) with random forests (RF); which we therefore call DT-RF. In DT-RF, the datasets to be analyzed are divided by a DT model, and RF models are constructed for each subdataset. This enables global interpretation of the data based on the DT model, while the RT models improve the prediction accuracy and enable local interpretations. Case studies were performed using three datasets, namely, those containing data on the boiling point of compounds, their water solubility, and the transition temperature of inorganic superconductors. We examined the proposed method in terms of its validity, prediction accuracy, and interpretability.
<Keywords:> Model interpretability, Predictive ability, Decision tree, Random forests, Regression model
<URL:> https://www.jstage.jst.go.jp/article/jccj/advpub/0/advpub_2020-0021/_article/-char/ja/
<Title:> Constructing Regression Models with High Prediction Accuracy and Interpretability Based on Decision Tree and Random Forests
<Author(s):> Naoto SHIMIZU, Hiromasa KANEKO
<Corresponding author E-Mill:> hkaneko(at)meiji.ac.jp
<Abstract:> Models for predicting properties/activities of materials based on machine learning can lead to the discovery of new mechanisms underlying properties/activities of materials. However, methods for constructing models that exhibit both high prediction accuracy and interpretability remain a work in progress because the prediction accuracy and interpretability exhibit a trade-off relationship. In this study, we propose a new model-construction method that combines decision tree (DT) with random forests (RF); which we therefore call DT-RF. In DT-RF, the datasets to be analyzed are divided by a DT model, and RF models are constructed for each subdataset. This enables global interpretation of the data based on the DT model, while the RT models improve the prediction accuracy and enable local interpretations. Case studies were performed using three datasets, namely, those containing data on the boiling point of compounds, their water solubility, and the transition temperature of inorganic superconductors. We examined the proposed method in terms of its validity, prediction accuracy, and interpretability.
<Keywords:> Model interpretability, Predictive ability, Decision tree, Random forests, Regression model
<URL:> https://www.jstage.jst.go.jp/article/jccj/advpub/0/advpub_2020-0021/_article/-char/ja/